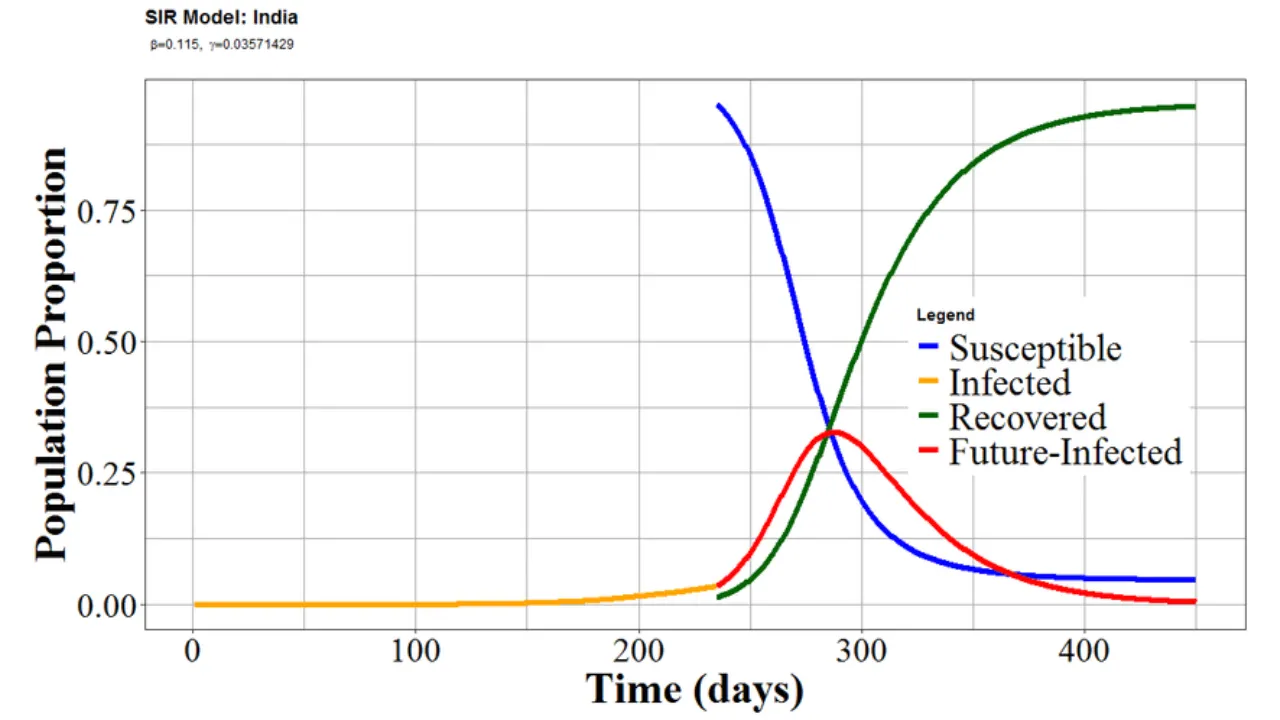
SIR COVID-19 prediction model: Predicting the spread of COVID-19 has been one of the most challenging yet necessary tasks in public health and data science. In a country as vast and diverse as India, forecasting infections, hospitalizations, and deaths can help policymakers plan ahead, allocate resources efficiently, and implement timely interventions. Models, especially compartmental ones like SIR, have been widely used to understand the dynamics of disease spread.
This article breaks down how the SIR – COVID-19 prediction model works, its role in pandemic forecasting in India, and how it integrates with real-world data. From data collection to model validation and deployment, we’ll look at the essential components that make this prediction model reliable and useful in guiding public health responses.
SIR – COVID-19 Prediction Model
The SIR – COVID-19 prediction model is a type of compartmental model used to simulate how diseases spread through a population. It divides people into three categories: Susceptible (S), Infected (I), and Recovered (R). As the virus spreads, individuals move from one compartment to another. This simple framework helps estimate how quickly an infection could grow or fade in a population, given certain conditions.
In India, where regional variations in population density, healthcare access, and mobility are significant, the SIR model offers a flexible foundation. It can be adjusted to local conditions, incorporated with other forecasting tools, and improved with real-time data for more accurate results.

Overview Table: Key Components of the SIR COVID-19 Prediction Model
| Component | Details |
| Data Sources | MoHFW, Worldometer, ICMR, Google Mobility Reports |
| Data Types | Cases, deaths, testing, vaccination, mobility, demographics |
| Model Types | SIR, SEIR, LSTM, ARIMA, hybrid models |
| Validation Metrics | MAE, RMSE, MAPE, R² |
| Deployment Needs | Real-time updates, dashboards, continuous monitoring |
| India-specific Factors | Regional data quality, population density, healthcare access |
Data Collection and Preprocessing
A reliable prediction model begins with accurate data. For India, data is gathered from various sources including:
- Ministry of Health and Family Welfare (official daily case numbers)
- Worldometer (global statistics with country-level details)
- ICMR (testing data)
- State Health Departments (regional information)
- Google Mobility Reports (movement patterns)
- Environmental and demographic data
Collected data includes daily infections, recoveries, deaths, testing rates, vaccination numbers, and population distribution. Before feeding this data into the model, it needs to be cleaned and processed. This includes handling missing values, smoothing out outliers, and normalizing the variables. Techniques like time-series decomposition are also used to detect trends and patterns.
Model Selection and Development
While the SIR model forms the core of many COVID-19 prediction frameworks, it is often used alongside or in comparison with other models:
- Time-Series Models: ARIMA, SARIMA, and exponential smoothing work well with historical trend data.
- Machine Learning Models: Regression, neural networks (especially LSTM), and SVMs are capable of learning patterns from complex data.
- Hybrid Approaches: Combining SIR with machine learning and time-series models helps enhance forecasting accuracy.
In an SIR model, the infection rate (β) and recovery rate (γ) are estimated from the data. The model then projects how the susceptible population transitions to infected and eventually recovered. It’s ideal for estimating the peak of infections and potential impact of interventions.

Model Training and Validation
Once the model is selected, it needs to be trained using historical data. A portion of the data is reserved for validation to test the model’s predictive ability. Key metrics used for evaluating performance include:
- MAE (Mean Absolute Error)
- RMSE (Root Mean Square Error)
- MAPE (Mean Absolute Percentage Error)
- R² (Coefficient of Determination)
Hyperparameter tuning is done to improve model performance, such as adjusting the learning rate in neural networks or tweaking β and γ in SIR models. Cross-validation helps ensure the model performs well across different time periods and regions.
Model Deployment and Monitoring
After validation, the model is deployed for real-time forecasting. This means it continuously receives updated data—daily case numbers, vaccination rates, etc.—and refines its predictions. A user-friendly dashboard is essential to present results to health officials and the public.
Monitoring is key. The model must adapt to changing trends like the appearance of a new variant or policy changes (e.g., lockdowns or school reopenings). Regular retraining ensures the predictions remain relevant and accurate.

Key Considerations for India
India presents unique challenges and opportunities for COVID-19 modeling:
- Regional Variations: Each state has different transmission patterns, testing rates, and healthcare capacity.
- Data Quality: In some regions, especially rural areas, data may be underreported or delayed.
- Healthcare Limitations: Hospital bed and ICU availability influence disease outcomes and should be factored into model assumptions.
- Population Density: Urban areas with high density may experience faster spread.
- Cultural Practices: Festivals, elections, and gatherings affect mobility and transmission risk.
In light of these differences, region-specific SIR models may be more effective than a single national model.
Example Workflow Using SIR and Neural Network
- Collect Data: Gather daily cases, mobility data, vaccination coverage.
- Preprocess: Clean missing values, normalize, and extract trends.
- Modeling:
- Use SIR to simulate general epidemic progression.
- Train an LSTM neural network on time-series data to fine-tune short-term forecasts.
- Use SIR to simulate general epidemic progression.
- Validate: Compare predictions with test data using MAE and RMSE.
- Deploy: Integrate with a dashboard and update predictions daily.
- Monitor: Track performance and retrain as new data or variants emerge.
FAQs
1. What is the SIR – COVID-19 prediction model used for?
It simulates how COVID-19 spreads through a population by categorizing people as Susceptible, Infected, or Recovered.
2. Why is modeling COVID-19 in India challenging?
India’s large, diverse population and variations in data quality make accurate forecasting complex.
3. Can SIR models predict new waves of infection?
They can estimate potential surges, especially when combined with real-time data and mobility trends.
4. How accurate are COVID-19 prediction models?
They are useful tools but not perfect. Forecasts provide estimates, not guarantees, and need regular updates.
5. What makes hybrid models effective?
Combining SIR with machine learning allows for both structured epidemic modeling and pattern recognition.
Final Thought
The SIR – COVID-19 prediction model continues to be a valuable tool in managing public health crises. While no model is perfect, combining epidemiological logic with real-time data and machine learning helps improve predictions and decision-making. In India’s complex and diverse landscape, adaptive, region-specific models are the key to planning a smarter response. Share your thoughts below or explore more about how prediction models are shaping the future of public health.









")